Past Research
Over the years I have worked on many research problems in a broad range of areas in CS, some with a successful outcome and some not.
Language models that skip over optional constituents
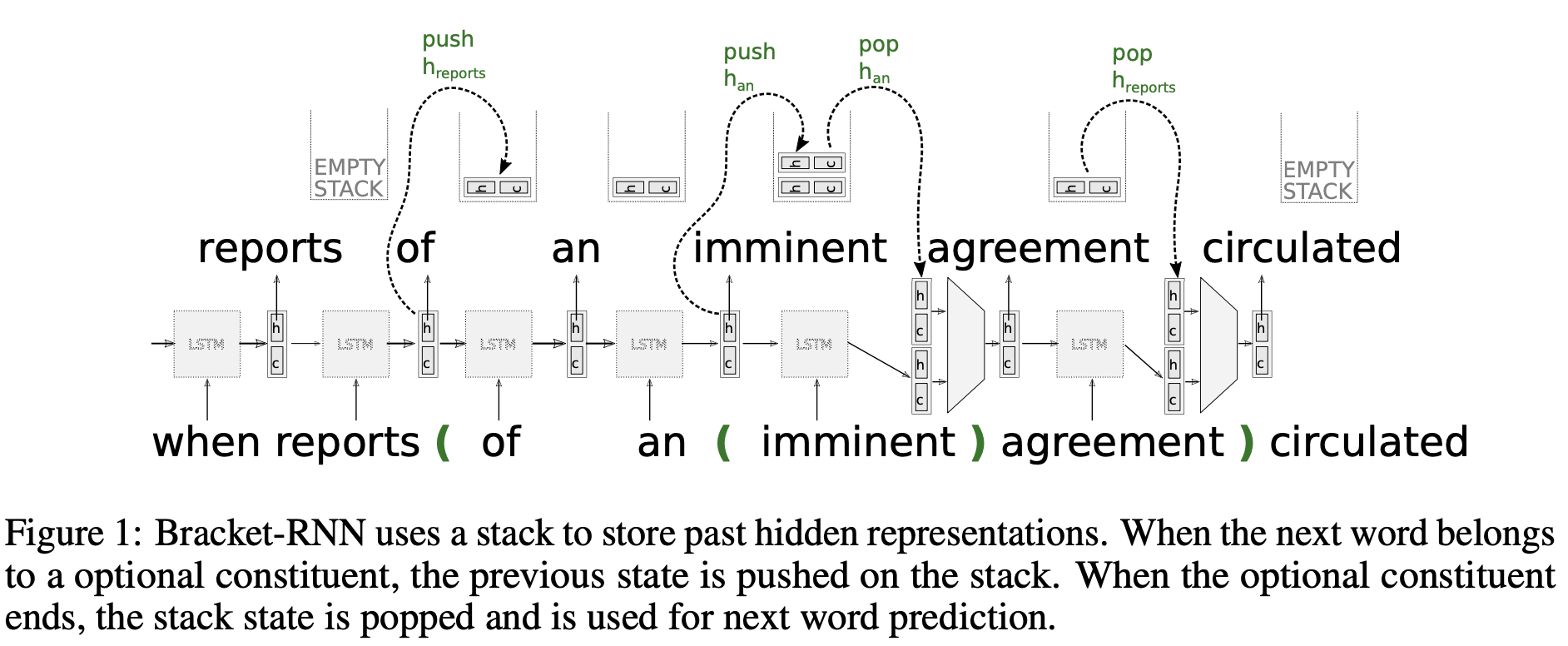 Words and phrases such as adjectives and adverbs - even though they add meaning - are optional for a sentence’s grammaticality.
Can we make language models more robust by teaching them that it is gramatically okay to skip over them?
Yes indeed! We modified RNNs to allow them to skip over constituent phrases and they showed massive improvements - 11 perplexity points - when we fed them the optional constituents.
The real question is, can they predict the optional constituents (as opposed to externally providing them) and then use those predictions to improve their language modelling ability?
Despite the theoretical promise of the method, we found that it was hard to predict when the optional constituent should end, especially for the long dependencies where we would expect the benefit to be the most.
While we found some overall improvements in perplexity, they seemed small compared to the computational cost of predicting the latent optional constituents.
We finally shelved this project because large transformer models with their cross attention mechanism reduced the utility of predicting latent linguistic structures to model long term context. Here is the poster that I presented at WeCNLP. This was work with Siva Reddy and Chris Manning
Words and phrases such as adjectives and adverbs - even though they add meaning - are optional for a sentence’s grammaticality.
Can we make language models more robust by teaching them that it is gramatically okay to skip over them?
Yes indeed! We modified RNNs to allow them to skip over constituent phrases and they showed massive improvements - 11 perplexity points - when we fed them the optional constituents.
The real question is, can they predict the optional constituents (as opposed to externally providing them) and then use those predictions to improve their language modelling ability?
Despite the theoretical promise of the method, we found that it was hard to predict when the optional constituent should end, especially for the long dependencies where we would expect the benefit to be the most.
While we found some overall improvements in perplexity, they seemed small compared to the computational cost of predicting the latent optional constituents.
We finally shelved this project because large transformer models with their cross attention mechanism reduced the utility of predicting latent linguistic structures to model long term context. Here is the poster that I presented at WeCNLP. This was work with Siva Reddy and Chris Manning
Knowledge Base Population
The task here is to read documents and populate a knowledge base with entities and relations between them. I was part of Stanford’s team for the TAC-KBP challenge in 2016 and 2017. By 2016, we had a mature extraction pipeline for English documents, but the errors in upstream systems would cascade to downstream components and reduce overall accuracy. I spent the summer of 2016 analyzing the errors in intermediate stages and fixing them, ultimately improving downstream performance. You can find more details in the paper Stanford at TAC KBP 2016: Sealing Pipeline Leaks and Understanding Chinese.
Subsequently, we realized that a major issue with evaluating any improvements is that the gold labels were annotated by TAC for a static set of relations extracted by systems last year. Thus during development, any new improvements that improve recall would get unduly penalized for predicting new relations that might have been correct but weren’t predicted by the previous systems. To fix that problem, we proposed a on-demand evaluation that gathers new annotations to accurately predict improvements. It would be prohibitively expensive to collect annotations for all new predictions, so we use importance sampling aimed to reduce bias and variance. This was joint work with Arun Chaganty, Chris Manning and Percy Liang and culminated with the EMNLP paper titled Importance sampling for unbiased on-demand evaluation of knowledge base population.
Temporal Networks and Counting Motifs
When edges in a network have timestamps - such as text messages (timestamped edges) sent between people (nodes) - they are called temporal networks. Patterns of edges in a network are called motifs; we define temporal patterns of timestamped edges as temporal motifs. Counting motifs in networks reveals characteristics about networks that are otherwise hidden. For instance, do people commincate with a single person at a time, or do they multiplex their communication with multiple people. We provide fast methods for counting temporal motifs and analyze many datasets to show that they reveal some expected and some surprising characteristics. My favorite algorithm by far is for counting 3-edge triangle motifs. This was joint work with Austin Benson and Jure Leskovec and you can find all the juicy details in the WSDM paper Motifs in Temporal Networks.